「Mac miniでAI」という流れ、どこから来たのか
「ChatGPTに社外秘のデータを入力するのが怖い」「クラウドAPIのコストが膨らんできた」「自分専用のLLMを常時稼働させたい」——そんな気持ちを持つエンジニアや個人開発者の間で、ローカルLLMの需要がじわじわと高まっています。
そしてその実行環境として、ここ1〜2年で急速に支持を集めているのが Mac mini(Apple M4チップ搭載) です。Qiita・Zenn・noteにはMac miniを使ったローカルLLM検証記事が次々と投稿され、「Mac miniでローカルLLMを動かすのが流行っているらしいので乗ってみた」という書き出しの記事まで登場しています。
では、なぜ数ある選択肢の中でMac miniなのか。ゲーミングPC、NVIDIAのGPUサーバー、自作マシン——選択肢はたくさんあるはずです。この記事では、Mac miniがローカルLLMの「定番機材」になった構造的な理由を深掘りしていきます。
ローカルLLMとは何か?まずおさらい
ローカルLLM(Local Large Language Model)とは、クラウドではなく自分のマシン上で動作する大規模言語モデルのことです。
ChatGPTやClaude ProなどのクラウドAIと比較したとき、ローカルLLMには以下のような特徴があります。
- プライバシー: 入力データが外部サーバーに送信されない
- コスト: 初期費用のみで月額料金が不要
- オフライン動作: インターネット接続が不要
- カスタマイズ性: モデル選択・設定の自由度が高い
一方で、従来のローカルLLM実行には「高性能なNVIDIA GPU(VRAM 24GB以上)が必要」という高いハードルがありました。RTX 4090は一時期30万円前後、現在は入手困難な状況が続いており、個人用途ではなかなか踏み出しにくい領域でした。
Mac miniが選ばれる5つの理由
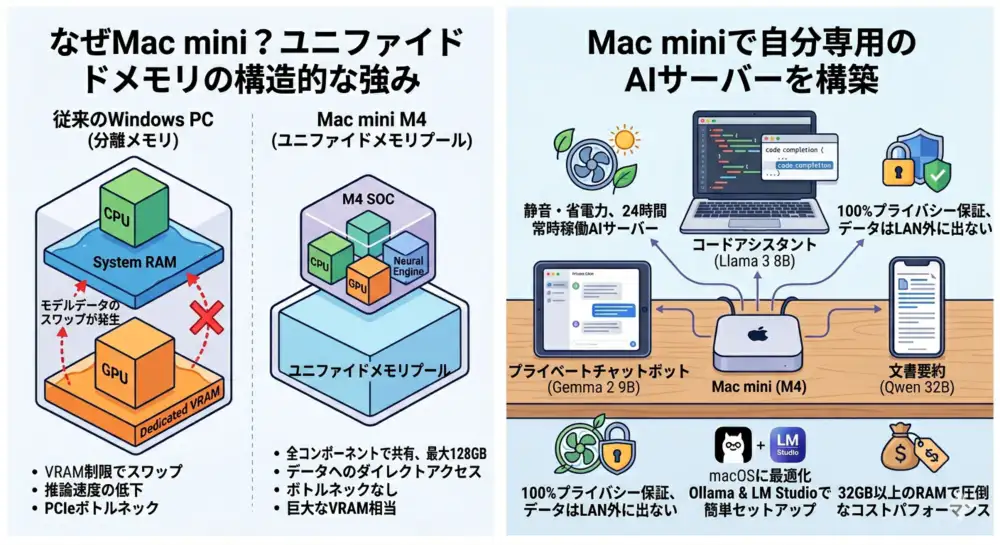
理由①:ユニファイドメモリがVRAM問題を根本から解消する
Mac miniがローカルLLMで支持される最大の理由は、ユニファイドメモリアーキテクチャ(UMA) にあります。
従来のWindowsマシンでは、AIはGPUのVRAMに依存して動作します。モデルの重みデータをVRAMに乗せて推論するため、VRAM容量がそのままモデルサイズの上限になります。VRAM 12GBのRTX 4070では、12GBを超えるモデルを動かそうとするとSSのスワップが発生し、推論速度が壊滅的に低下します。
Appleのユニファイドメモリでは、CPU・GPU・Neural Engineがひとつのメモリプールを共有します。つまり、メモリ32GBのMac miniは、ほぼ32GB相当のVRAMを持つ に近い環境で動作するということです。
この構造上の違いは、特に大規模モデルの推論において大きなアドバンテージになります。あるエンジニアが公開したベンチマークでは、Mac mini M4(64GB)がデュアルRTX 3090(VRAM合計48GB)よりもQwen3 32Bの推論速度で27%上回るという結果が出ています。RTX 3090は単体では936GB/sの高帯域を持ちますが、2枚構成にするとPCIe経由のGPU間通信がボトルネックになるためです。Appleのユニファイドメモリでは、そのボトルネックが存在しません。
理由②:コストパフォーマンスが圧倒的
ハードウェアのコストを比較すると、Mac miniの優位性はより明確になります。
| 構成 | 実効VRAM相当 | 価格目安 |
|---|---|---|
| Mac mini M4(16GB) | 〜16GB | 約9万円〜 |
| Mac mini M4(32GB) | 〜32GB | 約16万円〜 |
| Mac mini M4 Pro(64GB) | 〜64GB | 約28万円〜 |
| RTX 4090(24GB VRAM) | 24GB(GPU専用) | 約30万円〜(入手困難) |
| RTX 5090(32GB VRAM) | 32GB(GPU専用) | 100万円超 |
32GBの実効メモリを確保しようとしたとき、Mac miniはRTX 4090に匹敵またはそれ以上の費用対効果を持ちます。しかも24時間稼働時の消費電力も大幅に低く、電気代という観点のランニングコストでも有利です。
理由③:実用的な推論速度が出る
「コストが安くても遅ければ意味がない」という疑問はもっともです。実際のパフォーマンスはどうでしょうか。
ベンチマークデータをまとめると、以下のような傾向があります。
- Mac mini M4(16GB)+ 8Bモデル(4bit量子化): 18〜35トークン/秒
- Mac mini M4 Pro(64GB)+ 32Bモデル(Q4/Q5): 12〜18トークン/秒
- Mac mini M4(32GB)+ 14Bモデル(MLX形式): 非常に快適に動作
人間の平均読書速度は1分間に約400〜600文字程度です。1トークンはおおよそ0.7〜1文字に相当するため、10〜20トークン/秒でも「チャットとして普通に使える速度」をクリアします。32Bクラスのモデルであっても対話用途では十分実用的な速度が出ています。
なお、macOS向けに最適化されたMLX形式のモデルは、GGUF形式と比べて高速かつ省メモリで動作することが確認されており、Apple Siliconで使う場合はMLX形式を選ぶことで性能がさらに向上します。
理由④:セットアップのしやすさとエコシステムの成熟
ローカルLLMを動かすツールとして広く使われているOllamaは、macOSに対してネイティブ最適化されています。コマンド一発でモデルをダウンロードして実行できるため、CUDA環境の構築やLinuxドライバの格闘が不要です。
LM Studio も同様に、macOS向けのGUIが充実しており、非エンジニアでも直感的に操作できます。Ollama・LM Studioいずれも、Apple Siliconに対してMLXバックエンドでの最適化が進んでいます。
WindowsでNVIDIA GPUを使う場合、CUDA・cuDNN・ドライバの整合性を手動で管理する必要があります。Mac miniは購入後すぐに使える状態に近く、この「始めやすさ」が普及を後押ししています。
理由⑤:静音・省電力で24時間サーバー運用が現実的
Mac miniは非常に小型で静音設計です。ローカルLLMはLAN内の他端末から利用するサーバーとして動かすことが多く、「家のどこかに置いておける」「ファンの騒音が気にならない」という特性は、実用上の大きなメリットになります。
MacBookでフルパワーのローカルLLMを動かすと「想像以上にバッテリーが減った」という体験談が多く報告されています。Mac miniは常時電源接続のデスクトップ機であるため、電力を気にせず使い続けられる点も選ばれる理由のひとつです。
どのメモリ容量を選ぶべきか?
Mac miniはメモリ容量によって動かせるモデルが大きく変わります。購入前の選定基準として参考にしてください。
16GB:入門〜軽量用途
7B〜8Bの量子化モデル(Llama 3.1 8B、Gemma 2 9Bなど)をメインに使う場合は16GBでも十分です。ただし、長いコンテキストを扱う作業や複数の重いタスクを同時に行うと、メモリ不足でSSスワップが発生することがあります。メモリ容量の60%以下に収まるモデルを選ぶのが安定動作のコツです。
32GB:実用的なバランスポイント
32GBは多くのユーザーが「あともう少しメモリがあれば…」という経験を経て行き着く構成です。14B〜32Bクラスの4bit量子化モデルを快適に扱えるため、コーディング補完・文書処理・チャットボットなどの実用ユースケースを網羅できます。
64GB(M4 Pro):高度な用途・将来への投資
32B〜70Bクラスのモデルを安定して動かしたい場合、またはAIエージェントとして連続的な長いタスクを処理させたい場合は64GBが選択肢に入ります。単一ユーザーの用途であれば非常に強力な環境です。
Mac miniの限界と注意点
Mac miniを絶賛するだけでは不誠実なので、注意点も整理しておきます。
小さいモデルではNVIDIA GPUが速い。 7B以下の軽量モデルでは、RTX 3060搭載のWindowsノートPCの方が高速というベンチマーク結果もあります。NVIDIAの強みは特定規模のモデルに対する純粋な演算速度です。
メモリ上限を超えると壊滅的に遅くなる。 モデルのサイズがメモリ容量を超えると、macOSはSSDへのスワップを開始します。このとき推論速度が理論値の10トークン/秒から0.28トークン/秒まで低下するという報告もあり、メモリ容量の選定は非常に重要です。
複数ユーザーの同時接続には不向き。 ユニファイドメモリはKVキャッシュ(会話の文脈を保持するメモリ)も同じプールを消費するため、複数ユーザーが同時に長い会話をするサーバー用途では性能が落ちやすいです。
ファインチューニング(追加学習)には不向き。 学習用途は推論と異なり、オプティマイザのステートなど追加のメモリが必要になるため、Mac miniでは現実的ではありません。
AMD Ryzen AI Maxミニ PCの台頭
2025年後半から、AMD「Ryzen AI Max+ 395」搭載のミニPCがローカルAI市場に参入しています。Minisforum MS-S1 Maxなどは128GBのユニファイドメモリを持ち、理論メモリ帯域幅256GB/sとスペック上は競争力があります。
ただし、macOS Metal(Appleの推論フレームワーク)と比較して、AMD向けのROCmソフトウェアエコシステムはまだ成熟途上です。2026年初頭時点では、OllamaやLM Studioの最適化が一番進んでいるのは依然としてApple Siliconという状況が続いています。
今後AMD勢が台頭してきた場合、Mac miniの優位性はハードウェアよりもソフトウェアエコシステムの成熟度にかかってくるでしょう。
Mac miniはローカルAI時代の「合理的な選択」
Mac miniがローカルLLMで流行している理由は、ひとつの「革命的な機能」ではなく、複数の要因が重なって生まれたコストパフォーマンスの構造的な優位性にあります。
- ユニファイドメモリがVRAMの壁を実質的に解消した
- 手が届く価格でまとまったメモリ容量が確保できる
- Ollama・LM StudioなどのツールがmacOSに最適化されている
- 静音・小型で常時稼働のサーバー運用に向いている
「クラウドAIに情報を出したくない」「月額課金を減らしたい」「自前のAIサーバーを持ちたい」——そんな動機を持つ個人やスモールチームにとって、Mac mini M4は現時点で最もバランスのよい選択肢のひとつです。
もちろん、すべての用途に最適というわけではありません。重いモデル・大量同時接続・ファインチューニングが目的なら、より専用的なハードウェアの検討が必要です。しかし「まずローカルLLMを試してみたい」「実用的な私的AIサーバーを作りたい」という出発点であれば、Mac miniは非常に現実的な答えです。
よくある質問(FAQ)
Q. Mac mini M4の最小構成(16GB)でローカルLLMは実用になりますか?
A. 7B〜8Bの量子化モデルを1ユーザーで使う用途なら十分実用的です。18〜35トークン/秒程度の速度が出るため、チャット用途の応答速度としては問題ありません。ただし、長いコンテキストや複数タスクの同時実行には32GBが推奨です。
Q. Mac miniとWindowsゲーミングPCはどちらがローカルLLMに向いていますか?
A. 32B以上の大きなモデルを動かしたい場合、同価格帯ではMac miniの方がメモリ容量で優位です。7B以下の軽量モデルに限ればNVIDIA GPUが速いですが、RTX 4090は現在入手困難で価格も高騰しています。セットアップのしやすさも含めると、多くの個人ユーザーにはMac miniが合理的な選択です。
Q. Mac miniでローカルLLMを動かすのに必要なツールは何ですか?
A. OllamaまたはLM Studioがあれば、コマンドラインまたはGUIでモデルのダウンロードから実行まで完結します。どちらもApple Siliconに最適化されており、macOSへのインストールは数分で完了します。
Q. ユニファイドメモリとVRAMは何が違うのですか?
A. 従来のGPU搭載PCでは、CPU用のシステムRAMとGPU用のVRAMは物理的に分離されています。Appleのユニファイドメモリは、CPU・GPU・Neural Engineがひとつのメモリプールを共有する設計です。データのコピーが不要になるため、大きなモデルの読み込みと推論において効率が高く、VRAM容量の壁が事実上なくなります。
本記事の情報は2026年4月時点のものです。ハードウェアおよびソフトウェアの最新情報は各公式サイトでご確認ください。



